原创猫:版权是大模型无法避免的问题
 收藏
收藏
- 复制链接
- 微信扫一扫
原创猫:版权是大模型无法避免的问题

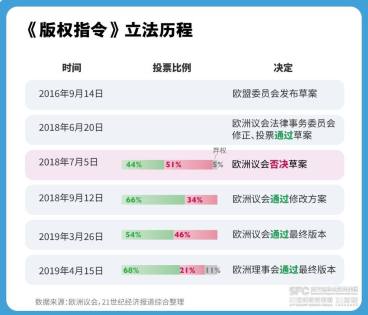
在数字时代的浪潮中,人工智能技术得到了飞速的发展,大型语言模型(LLM)作为其中的佼佼者,已经开始在各个领域中发挥重要作用。然而,随着这些模型应用范围的扩大,版权问题也逐渐浮出水面,成为了无法逃避的议题。版权不仅关乎创作者的权益,更是数字时代创新发展的基石。因此,我们必须正视版权问题,为大型语言模型的应用和发展创造健康的环境。
大型语言模型在训练过程中需要汲取大量的知识,这些知识来源于各种文本资源。在使用过程中,模型可能会生成与已有作品相似或相同的内容,这就涉及到版权问题。例如,在生成文章、诗歌、代码等文本时,如果模型直接复制了他人的作品,而未经过授权,那么这就构成了侵权行为。因此,大型语言模型的应用者需要在使用前明确版权归属,确保所使用的数据资源已经获得了合法授权。
版权问题不仅关乎创作者的个人利益,更是数字时代创新发展的保障。在创新的过程中,创作者需要投入大量的时间和精力,他们希望自己的成果能够得到应有的回报。而版权制度正是为了保障创作者的这种权益,鼓励更多的人投入到创新活动中。对于大型语言模型而言,只有在尊重版权的前提下,才能充分发挥其潜力,推动人工智能技术的进步。
面对版权问题,我们应该采取积极的措施来应对。首先,政策制定者需要完善相关法律法规,明确大型语言模型在版权保护中的地位和责任。同时,还需要加强对侵权行为的打击力度,让违法者付出应有的代价。其次,大型语言模型的开发者和应用者也需要自觉遵守版权规定,确保在使用过程中不侵犯他人的权益。此外,他们还需要积极寻求与版权方的合作,共同推动人工智能技术与版权保护的和谐发展。
在解决版权问题的过程中,我们还需要关注一些具体的实践案例。例如,有些大型语言模型在生成文章时,可能会无意识地抄袭他人的作品。这时,我们需要对模型进行调优,提高其生成内容的原创性。同时,我们还需要建立一套完善的版权保护机制,确保创作者的作品能够得到及时、有效的保护。
总之,版权是所有大型语言模型都无法逃避的问题。在推动人工智能技术发展的同时,我们必须高度重视版权保护工作。只有让创作者在创新过程中得到充分保障,才能激发更多的创新活力,推动数字时代的繁荣发展。让我们共同努力,为大型语言模型的应用和发展创造一个健康、和谐的环境。