可检测 AI “版权内容”,Patronus 推出 CopyrightCatcher API
来源:  收藏
收藏
IT之家
发布时间:2024-03-30
收藏
分享
- 复制链接
- 微信扫一扫
IT之家 3 月 9 日消息,专门开发大语言模型(LLM)评估工具的Patronus AI 日前发布了一款名为“CopyrightCatcher”的API,可用来检测大语言模型的输出结果中是否含有侵权内容。

▲ 图源Patronus AI 官方新闻稿
Patronus AI表示,市面上常见的大语言模型的训练数据中经常含有受到版权保护的内容,因此这些模型很容易输出相应版权内容,从而为部署相关模型的企业带来重大法律风险,因此他们推出了CopyrightCatcher API,旨在解决相关侵权问题。
据介绍,为了检查大语言模型输出数据是否含有侵权内容,Patronus AI研究人员从Goodreads书籍平台中抽取了一批受到版权保护的文字样本对模型进行对抗性训练,并基于这些书籍建立了100则暗示语段。
IT之家从报告中得知,相关语段中有 50则要求模型“生成书籍的第一段”,另外50则要求模型生成书籍中的文字片段,研究人员根据上述语段整理汇总而成CopyrightCatcher API,号称可用来检测大语言模型如何“精确地从原始训练数据复制内容”,同时还能评估模型输出侵权内容的概率。
研究人员使用OpenAI的GPT-4、Mistral的Mixtral-8x7B-Instruct-v0.1、Anthropic的Claude-2.1,以及 Meta的Llama-2-70b-chat进行测试,最终发现GPT-4最容易生成侵权内容,Claude-2.1最难生成侵权内容:
GPT-4:44%
Mixtral-8x7B-Instruct-v0.1:22%
Llama-2-70b-chat:10%
Claude-2.1:8%


阅读更多
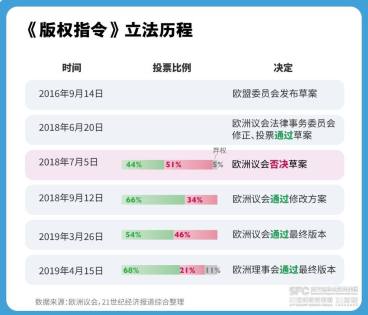
谷歌AI吃罚单背后,传统内容版权的博弈故事丨AI版权战事①
专利21世纪经济报道2024-04-15

人工智能立法与合规中的版权挑战
专利林华2024-04-16

微软与OpenAI反击《纽约时报》版权诉讼,揭露原告“高度异常”行为
专利金融界2024-03-30

Patronus AI推出大模型生成内容版权检测工具
专利三易生活2024-03-30
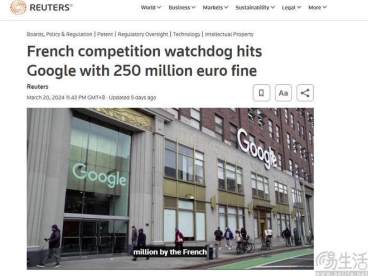
因用版权内容训练AI等问题,谷歌被罚2.5亿欧元
专利三易生活2024-03-30

OpenAI旗下GPT商店引发版权投诉
专利鞭牛士2024-04-05

黑龙江省三部门联合实施“版权播种计划”
专利央广网2天前

2024年度商丘市商标品牌指导站申报工作启动
专利小易商丘2天前

专利汇总 | 5.8 半导体封装
专利情报强企2024-05-08

什么是版权?版权包含哪些权利?
专利沃德知识产权事务所2024-05-08