2024人工智能指数报告(二):技术性能
 收藏
收藏
- 复制链接
- 微信扫一扫
神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:从2017年开始,斯坦福大学人工智能研究所(HAI)每年都会发布一份人工智能的研究报告,人工智能指数报告(AII),对上一年人工智能相关的数据进行跟踪、整理、提炼并进行可视化。这份指数报告被认为是关于全球人工智能发展状况最可信、最权威的来源之一。正值人工智能对社会的影响达到前所未有的时刻,前不久他们刚刚发布了第七份报告。今年的报告扩大了研究范围,以便更好地概括技术进步、公众看法等情况。整份报告分为八章,分别总结了人工智能的研发、技术性能、负责任的人工智能、经济、科学与医学、教育、政策与治理、多样性、舆论等方面的情况。我们选取部分编译出来,分四部分刊出,此为第二部分。

第二章:技术性能
概述
技术性能这一章将对2023年人工智能的进展进行全面概述。首先从对人工智能技术性能的简要概述开始,跟踪其大概的演进方向。然后再仔细审视各种人工智能能力,包括语言处理、编程、计算机视觉(图像与视频分析)、推理、音频处理、自治智能体、机器人及强化学习等能力在内的现状。本章还重点聚焦过去一年人工智能研究取得的重大突破,讨论了如何通过提示、优化及微调来提升大语言模型的性能,并最终探讨了人工智能系统对环境的影响。
本章摘要
- 人工智能在某些任务(但不是全部)的表现上超过了人类。人工智能在若干基准测试中的表现已超越人类,其中包括图像分类、视觉推理及英语理解等; 不过,对于数学竞赛、视觉常识、推理以及规划等更复杂任务,人工智能依然比不过人类。
- 多模态人工智能来了。传统人工智能在适用范围上一度存在局限性,比如语言模型擅长文本理解,但图像处理不行,反之亦然。不过,随着最近谷歌的 Gemini 以及 OpenAI 的 GPT-4 等强大的多模态模型的出现,人工智能展现出其灵活性,证明了自己图像、文本乃至音频的处理能力。
- 涌现出难度更高的基准测试。ImageNet、SQuAD 与 SuperGLUE等传统的基准测试对人工智能已构不成挑战, 研究者开始推出了更具挑战性的测试,如 2023 年冒出来的 SWE-bench、HEIM、MMMU、MoCa、AgentBench 及 HaluEval, 分别测试的是编码、图像生成、推理、道德判断、智能体行为与幻觉评估。
- 更好的人工智能意味着更好的数据,更好的数据又意味着更好的人工智能。像 SegmentAnything 、 Skoltech 这样的新的人工智能模型正被用来生成专门的数据,供执行图像分割与 3D 重建等任务。数据对于人工智能性能的改进至关重要。用人工智能来生成更多数据增强了当前的能力,并为将来的算法改进,尤其是更困难的任务扫清障碍。
- 人类评估开始介入。随着生成式模型生成出高质量的文本、图像等,评估方式正逐渐从传统的ImageNet或SQuAD等计算化排名逐渐转向包含有人类评价的系统,如 Chatbot Arena Leaderboard。公众对人工智能的感受正日益成为跟着人工智能进展的重要考虑因素。
- 因为大语言模型,机器人变得更灵活了。语言模型与机器人的融合诞生出像 PaLM-E 、 RT-2 这样更灵活的机器人系统。这些模型除了改善机器人的能力以外,还能提出问题,这是机器人朝着能更有效地与现实世界互动迈出的重要一步。
- 对AI 智能体研究变得更专业了。AI 智能体是指能在特定环境下自主运行的系统,这类系统的研发一直是计算机科学家面临的一大挑战。不过,新兴研究表明,这些智能体在自主运行的能力上有了显著提升,现在它们不仅能够精通类似 Minecraft 这样的复杂游戏,还能有效地完成在线购物、研究助理等现实世界的任务。
- 闭源大语言模型远胜开源。在10项选定的基准测试当中,闭源模型均超过了开源模型,性能优势的中位数达到了 24.2%。闭源相对开源的这种性能差异对于人工智能政策之争具有深远意义。
重要模型发布的时间线
- 2023/3/14,Claude,语言模型,Anthropic,Claude 是 Anthropic 推出的首个公开的语言模型,后者是 OpenAI 主要的竞争者之一。模型的目标是尽可能地做到有帮助作用、诚实、无害。
- 2023/3/14,GPT-4,语言模型,OpenAI,GPT-4 在上一代 GPT-3 的基础上进行了优化,现已成为目前最强大的几款语言模型之一,其表现甚至超过了人类。
- 2023/3/23,Stable Diffusion v2,文生图模型,Stability AI,Stability AI 的最新版 Stable Diffusion v2 提高了图片的分辨率和质量,令文生图的转换更精准,更高质量。
- 2023/4/5,Segment Anything,图像分割,Meta,Meta 的 Segment Anything可以利用零样本泛化技术分离图像中的对象。
- 2023/7/18,Llama 2,大语言模型,Meta,Meta 旗舰大语言模型的更新版,开源。其小型版(7B 和 13B)尽管规模不大,但性能出色。
- 2023/8/20,DALL-E 3,文生图模型,OpenAI,OpenAI 文生图模型 DALL-E 的改进版。
- 2023/8/29,SynthID,数字水印,Google, DeepMind,SynthID 是一个专门给人工智能生成的音乐和图像添加水印的工具,即便图像被修改了,水印仍能检测出来。
- 2023/9/27,Mistral 7B,大语言模型,Mistral AI,法国 Mistral AI 公司新推出的 Mistral 7B 模型,参数规模达到 70 亿,性能在同类产品领先,超过了 Meta Llama 2 的 13B 版本。
- 2023/10/27,文心大模型(Ernie) 4.0,大语言模型,百度
 推出的文心大模型 4.0中国目前性能最强的几款大语言模型之一。
推出的文心大模型 4.0中国目前性能最强的几款大语言模型之一。 - 2023/11/6,GPT-4 Turbo,大语言模型,OpenAI,这款升级版的大语言模型有 128K 的上下文窗口,价格还降低了。
- 2023/11/6,Whisper v3,语音转文本模型,OpenAI,OpenAI 的 Whisper v3 是一个开源的语音转文字模型,因具有更高的准确率和更广泛的语言支持而受到好评。
- 2023/11/21,Claude 2.1,大语言模型,Anthropic,Claude 2.1有着业界领先的 200K 上下文窗口,能够更好地处理包括长篇文学作品在内的复杂内容。
- 2023/11/22,Inflection-2,大语言模型,Inflection,Inflection的创办者是原 DeepMind 的 Mustafa Suleyman,Inflection-2是这家初创企业退出的第二款大语言模型 ,这标志着 LLM 领域竞争的加剧。
- 2023/12/6,Gemini,大语言模型,谷歌,Gemini的出现让GPT-4有了一个强大的竞争对手,其派生之一 Gemini Ultra 在众多评测中的表现超越了 GPT-4。
- 2023/12/21,Midjourney v6,文生图模型,Midjourney,Midjourney 的这个最新版本有着更直观的操作提示以及更高的图像质量,极大地优化了用户体验。
人工智能性能现状
截止至 2023 年,人工智能在多项任务上的表现已经超过了人类,图 2.1.16 展示了在9项人工智能基准测试(分别测试了9项代表性的任务,比方说图像分类或基础阅读理解)中人工智能系统相对于人类基准所取得的进步。过去几年,人工智能在图像分类( 2015 年)、基础阅读理解(2017 年)、视觉推理(2020 年)、自然语言推理(2021 年)等多个领的表现域已经超越了人类。不过,截止 2023 年,人工智能在某些领域,尤其是那些牵涉到更高级认知的任务,如视觉常识推理与高级数学解题(竞赛问题)等,还没能超过人类。
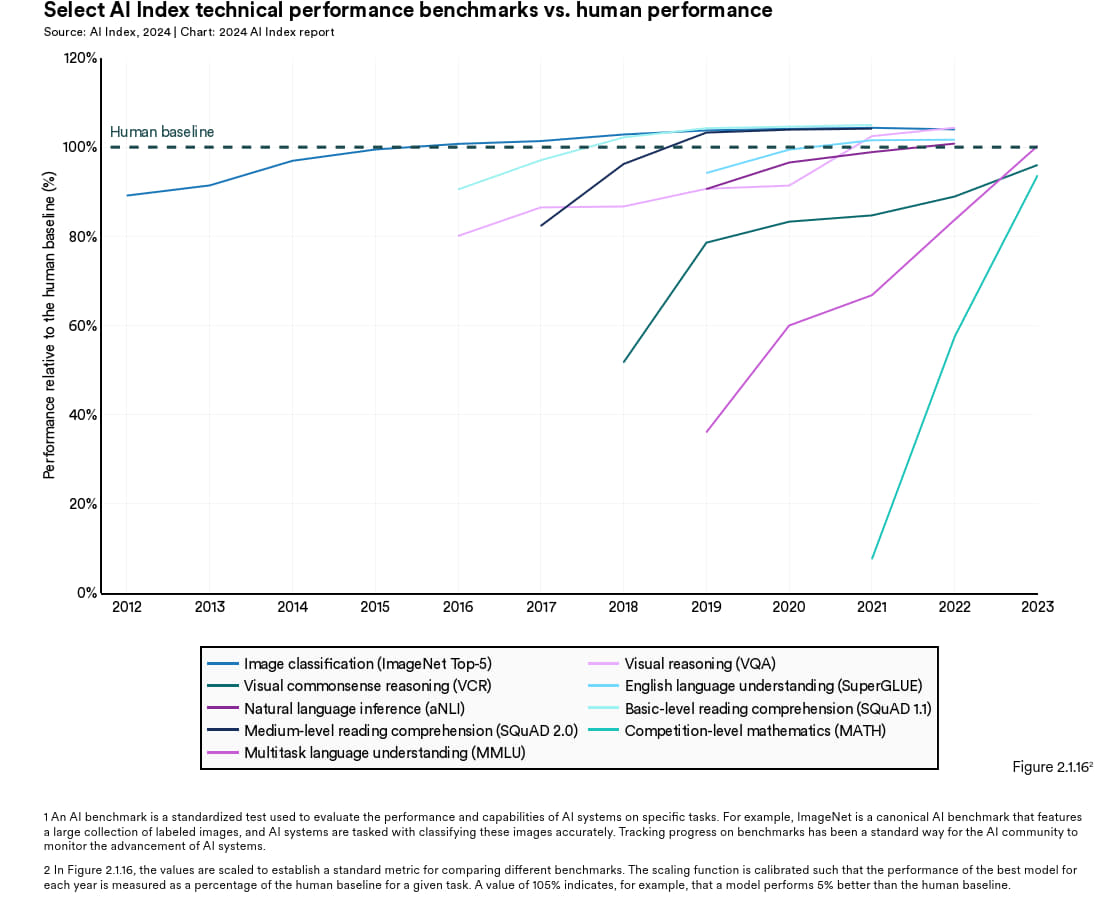
图2.1.16
2.2 语言
自然语言处理 (NLP) 可让计算机理解、解释、生成及改写文本。当前的一些顶尖的模型,如 OpenAI 的 GPT-4 与 Google 的 Gemini,可以生成流畅且有条理的文本,并表现出卓越的语言理解能力 (见图 2.2.1)。现在,这些模型还能处理不同的输入方式,比如图像与音频 (见图 2.2.2)。
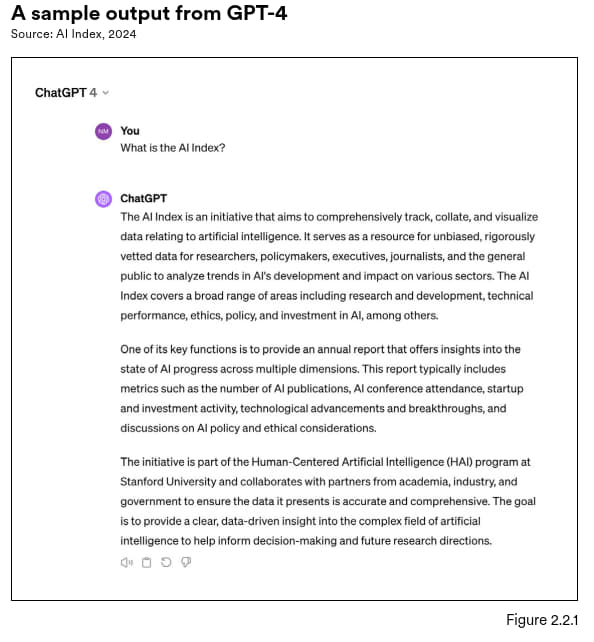
图2.2.1

图2.2.2
理解
英语理解挑战人工智能系统用各种方式理解英语,比如阅读理解,逻辑推理等。下面介绍其中一项基准测试的情况。
HELM:语言模型全面评估
如上所述,近些年来大语言模型在包括 SQuAD(回答问题)、 SuperGLUE(语言理解)在内的传统英文基准测试中以及超越了人类。这种快速进步促使我们需要更全面的评测标准。
2022 年,斯坦福的研究人员推出了 HELM(Holistic Evaluation of Language Models),这是一个旨在全面评估大语言模型在多种场景下表现的评测标准,评测范围涵盖阅读理解、语言理解以及数学推理等领域。HELM 通过评估 Anthropic、Google、Meta 和 OpenAI 等领先企业的模型,并用“平均胜率”(mean win rate)作为跟踪模型在各场景下平均表现的指标。截至 2024 年 1 月,GPT-4 以 0.96 的平均胜率在总榜排名第一(图 2.2.3);不过,在不同类型的任务中,表现最佳的未必都是GPT-4(见图 2.2.4)。
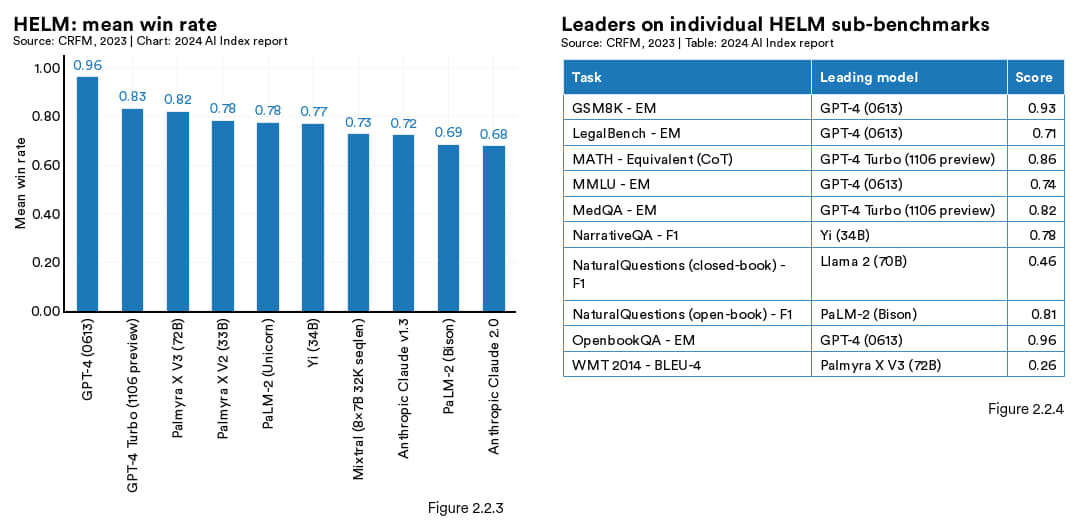
左图:图2.2.3 右图:图2.2.4
生成
在生成任务当中,测试的目标是看人工智能模型生成流利、实用的语言响应的能力。
Chatbot Arena Leaderboard
有能力的LLM崛起使得理解公众更偏爱哪些模型变得愈发重要。2023年推出的Chatbot Arena Leaderboard是第一个全面评估公众对大语言模型偏好的工具。这个排行榜会采取让2个不具名的模型PK的方式,由用户投票选出自己更喜欢哪个模型的生成(图 2.2.7)。截止 2024 年初,该平台已经收集了超过 20 万张投票,用户票选最高的是 OpenAI 的 GPT-4 Turbo (图 2.2.8)。

图2.2.7
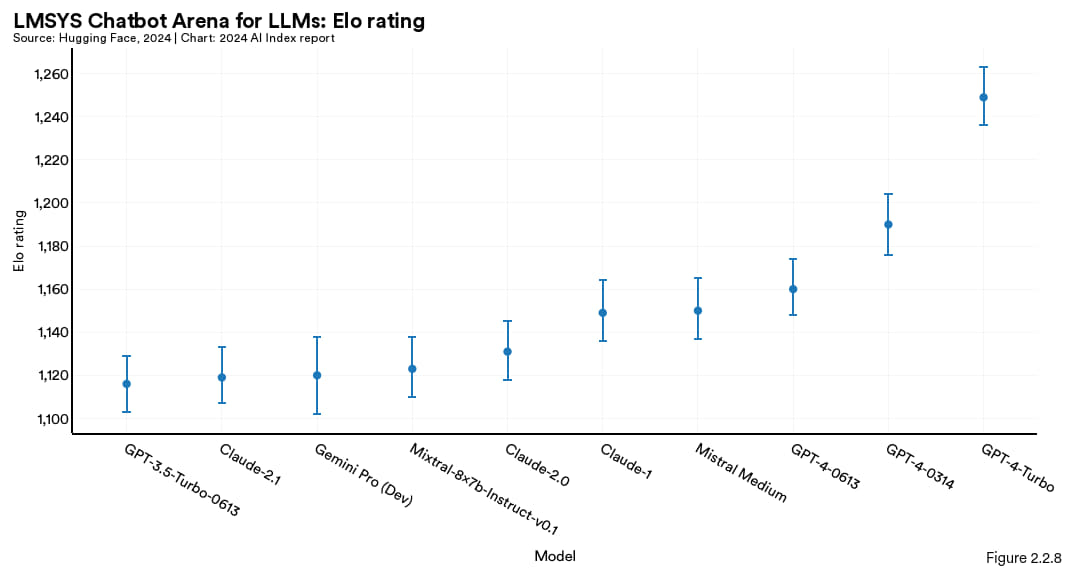
图2.2.8
事实性与真实性
尽管成就卓越,但大语言模型仍旧容易出现事实不准确以及内容幻觉——也就是创建出貌似真实,但却是虚假的信息。LLM产生幻觉在现实世界不乏例子(比如某些法庭案件),突出表明我们需要密切关注模型的事实性趋势。
HaluEval
正如我们之前提到那样,大语言模型往往会产生幻觉,如果是广泛应用在类似法律和医疗这样的关键领域的话,出现幻觉的情况时尤其会令人担忧。虽然很多研究都在探究幻觉产生的原因,但对大语言模型幻觉的产生频率以及在什么地方容易产生幻觉的研究还相对较少。
2023 年新推出的基准测试HaluEval就是专门用来评估大语言模型的幻觉问题的。该基准包含了超过 35000 个样本,里面既包括有幻觉也有正常的内容,用来对大语言模型进行分析和评价 。研究表明,ChatGPT 的回答约有 19.5% 的内容是捏造的不可验证信息,其中涉及语言、气候及技术等多个领域。此外,该研究还检验了目前的大语言模型识别幻觉的能力。图 2.2.12 展示了部分顶尖大语言模型在不同任务中识别幻觉的能力,其中包括问答、知识驱动的对话以及文本摘要等。这些发现突出表明幻觉问题的严重性与持续性。
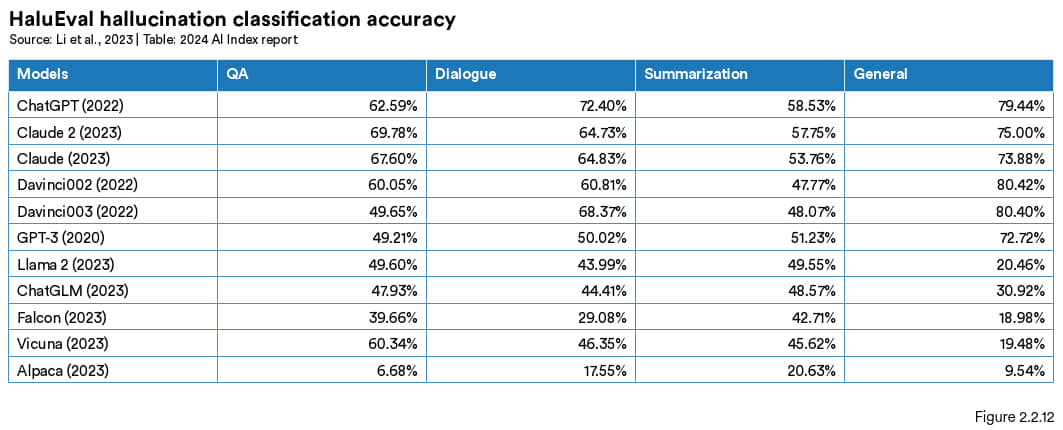
图2.2.12
2.3 编码
生成
人工智能模型被赋予了许多任务,去挑战其生成有用代码或解决计算机科学问题。
SWE-bench
随着人工智能系统编程能力的改善,用更有挑战性的任务对某些进行基准测试也就显得愈发重要。2023 年 10 月,研究人员引入了 SWE-bench ,这个新的数据集含有2294 个软件工程问题 (图 2.3.3),源自真实的 GitHub Issue以及热门的 Python 库 。该数据集对人工智能的编程能力提出了更高的要求,需要人工智能系统协调多个功能之间的变更,与不同的运行环境交互,还要进行复杂的逻辑推理。
即便最先进的大语言模型也要面临 SWE-bench 的的严峻挑战。在这些模型当中,Claude 2 模型的表现最好,但也仅解决了其中 4.8% 的问题 (图 2.3.4)。2023 年SWE-bench 上表现最佳的模型(Claude 2)成绩比 2022 年的最佳模型(OpenAI GPT 3.5)成绩高出 4.3 个百分点。
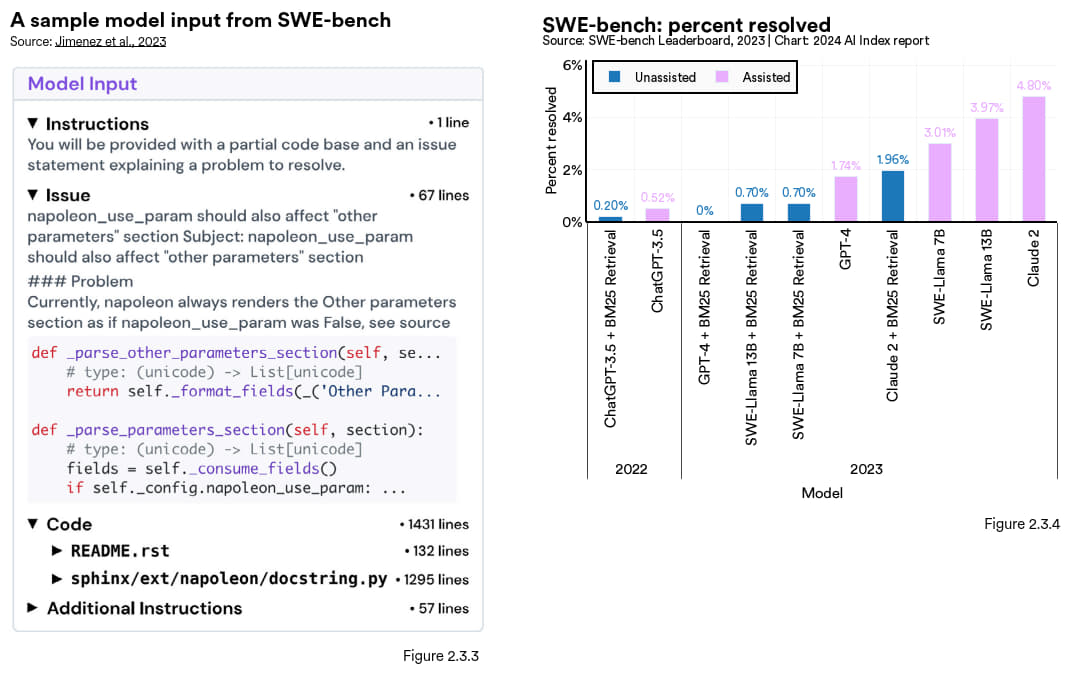
左图:2.3.3 右图:2.3.4
2.4 图像计算机视觉与图像生成
生成
图像生成的目标是做出真假难辨的图像。目前的图像生成技术已经非常先进,大部分人已难以分辨人工智能生成的人脸图像与真实人脸图像的差别。
HEIM(文生图模型全面评估)
随着 AI 文字转图片系统的快速进步,人们开发了更为复杂的评估方法。2023 年,斯坦福的研究人员推出了文生图模型全面评估 (HEIM) ,该基准测试从 12 个对实际应用极为重要的关键维度对图像生成工具进行全面评估,比如图像文本对齐 (image-text alignment)、图像质量 (image quality) 及美感 (aesthetics)等。模型评估采取人工评价方式,这一点非常关键,因为很多自动化指标难以精确地评价图像的各个方面。
HEIM 的研究结果显示,没有一个模型能在各项指标都能表现最佳。在评估图像文字对齐度(也就是生成图像与输入文字的契合程度)时,OpenAI 的 DALL-E 2 表现最为出色(见 图 2.4.3)。在图像质量(判断图像是否接近真实照片)、美感(视觉吸引力的评估)及创新性(图像生成新颖性,避免侵权的能力)上,基于Dreamlike Photoreal模型的 Stable Diffusion 得分最高(见 图 2.4.4)。

上:图2.4.3 下:图2.4.4
指令遵从
在计算机视觉,指令遵从是指视觉语言模型解释与图像相关的文本型指令的能力。比方说,给一些食材的图片交给人工智能系统,让后者给出如何用这些食材来准备一顿健康美食的建议。对于开发先进的人工智能助理来说,有个能力强的遵从指令的视觉语言模型是必要的。
VisIT-Bench
2023 年,产业界与学术界的一群研究人员推出了 VisIT-Bench,这个基准测试包含有大约 70 类指令,涉及 592 项挑战性很强的视觉 - 语言任务,比方说情节分析、艺术知识以及地点理解等 。到 2024 年 1 月截止时,GPT-4V (GPT-4 Turbo 的视觉版)是 VisIT-Bench 的领头羊,其 Elo 分数达到了 1349 分,略高于人类在该基准测试的得分 (图 2.4.9)。
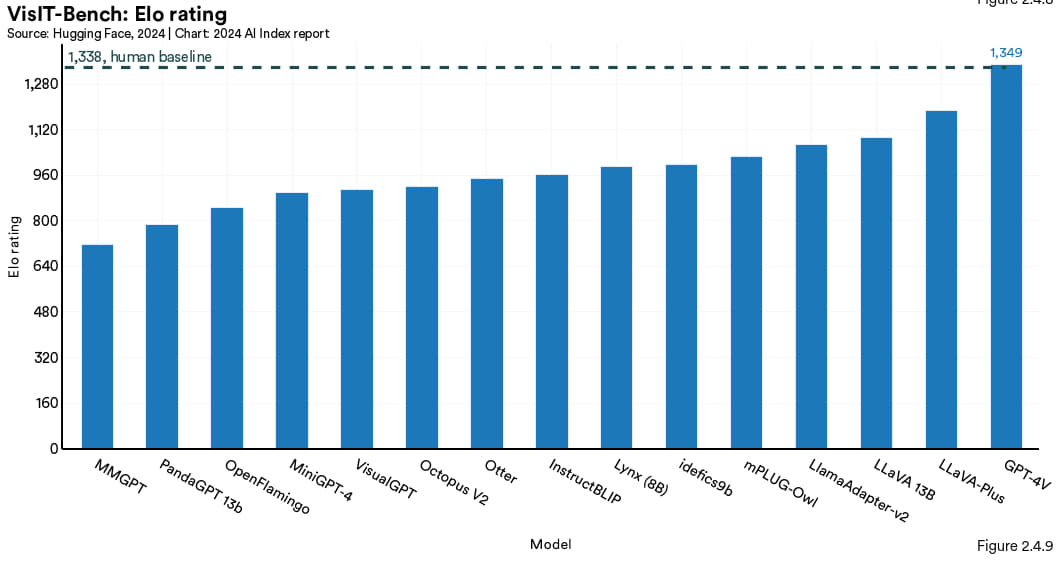
图2.4.9
编辑
图像编辑是指基于文本提示利用人工智能修改图像。这种人工智能辅助的方案中现实世界有着广泛应用,比如在工程、工业设计以及电影制作等均有用武之地。
EditVal
由文本指导的图像编辑技术尽管前景广阔,但目前仍缺少能准确评估编辑工具是否按照提示的可靠方法。新推出的基准测试 EditVal 就是专门用来评估这个的。该基准测试评估了 13 种以上的编辑方式(如增加物体或调整物体位置),覆盖了 19 类物体,已应用于测试包括 SINE 与 Null-text 在内的八中文本指导型图像编辑技术。这些编辑任务自 2021 年以来的表现提升可见图 2.4.11。
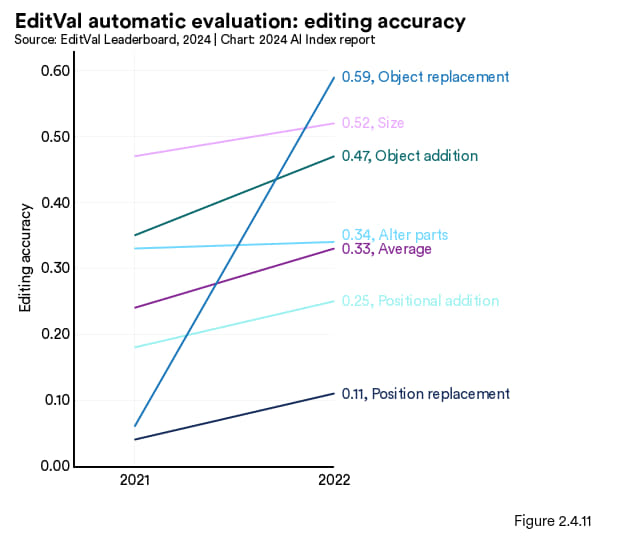
图2.4.11
图像分割
研究焦点
Segment Anything
Segment Anything是Meta 研究团队2023 年推出的一个项目,里面不仅有一个划时代的能分割一切的模型 (Segment Anything Model, SAM) ,还有一个庞大的 SA1B 图像分割数据库。SAM 模型作为第一批具备广泛通用性,且能在没有经过任何针对性训练的情况下(zero-shot),直接用于新的任务和数据分布。Segment Anything 在 16 个数据集(总共23个)当中的表现均超过了 RITM 等领先方案 (图 2.4.17)。评估Segment Anything用的指标是交并比 (Intersection over Union, IoU)。
在人类标注者的协助下,Meta 用SAM创建了 SA-1B 数据库,里面涵盖了超过 1 亿个分割图案,总计 1100 万张图像 (图 2.4.16)。这个庞大的数据库将极大加速未来图像分割技术的训练进程。通过与人类的合作,这个项目展示了如何更高效地利用人工智能创建大规模数据集,并利用这些数据集训练出更先进的人工智能。

图2.4.16
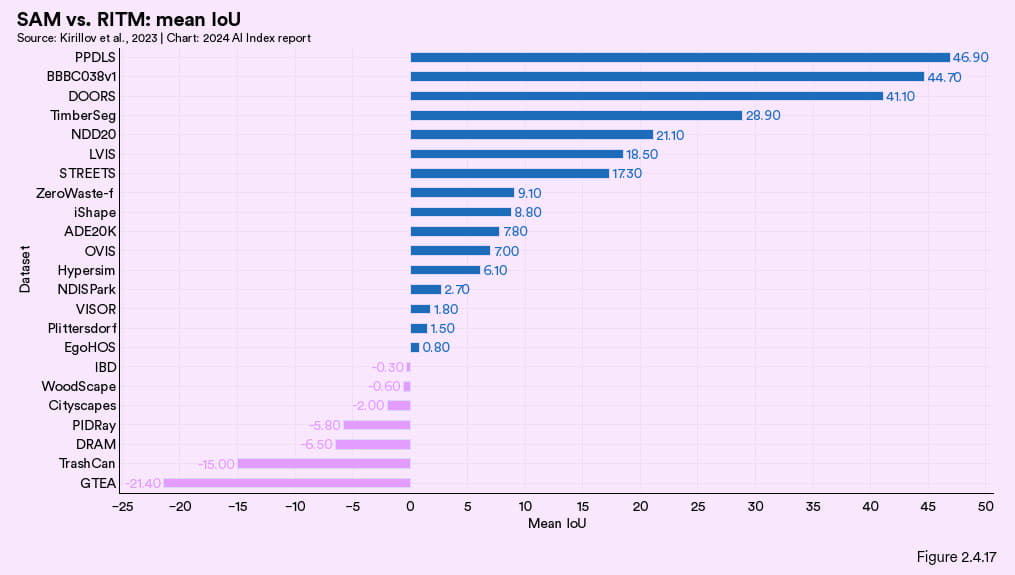
图2.4.17
2D图像的3D重构
三维图像重构是从二维图像创造出三维数字几何体的过程。此类重构可用于医疗影像、机器人学和虚拟现实领域。
报告聚焦了两项研究,分别是多视图3维表明重构数据集Skoltech3D,以及根据一张图像生成完整3D模型的新方法RealFusion。下图分别是其表现的对照情况。
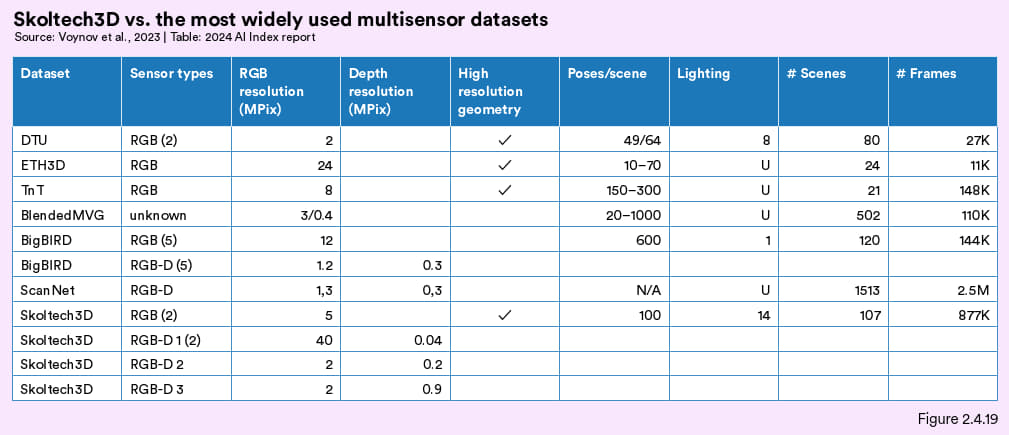
图2.4.19
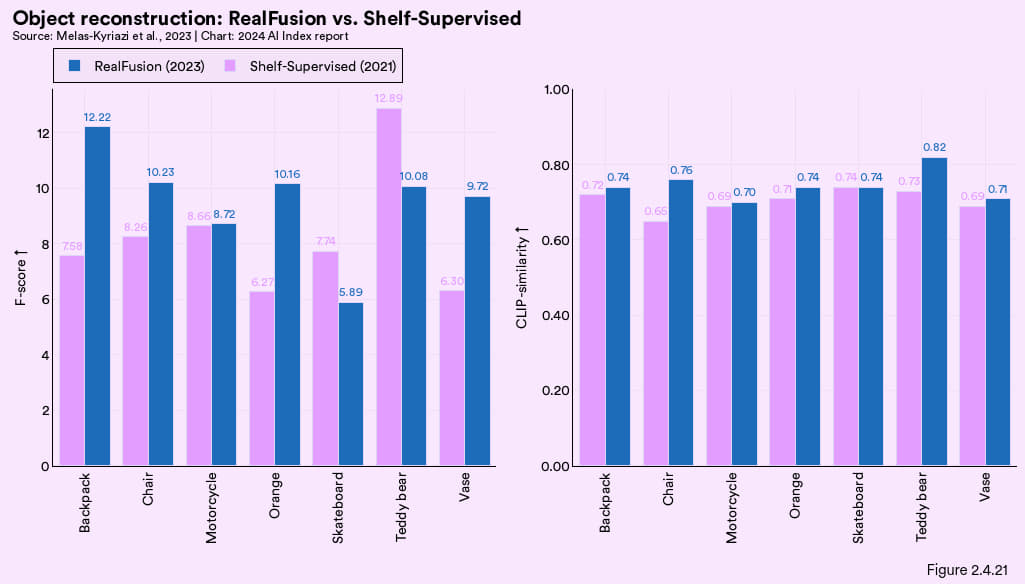
图2.4.21
2.5 视频计算机视觉与视频生成
生成
视频生成是指根据文本或图像利用人工智能生成视频。
UCF101
UCF101 是一个真实动作视频的数据集,涵盖了 101 种动作类别。最近,这个数据集被用来评估视频生成技术的效果。比方说,2023年表现最佳的模型,W.A.L.T-XL,在FVD16 这项指标的得分为 36 分(编者注:分值越低表明生成质量越高),比去年的最好成绩的还少一半 (图 2.5.2)。
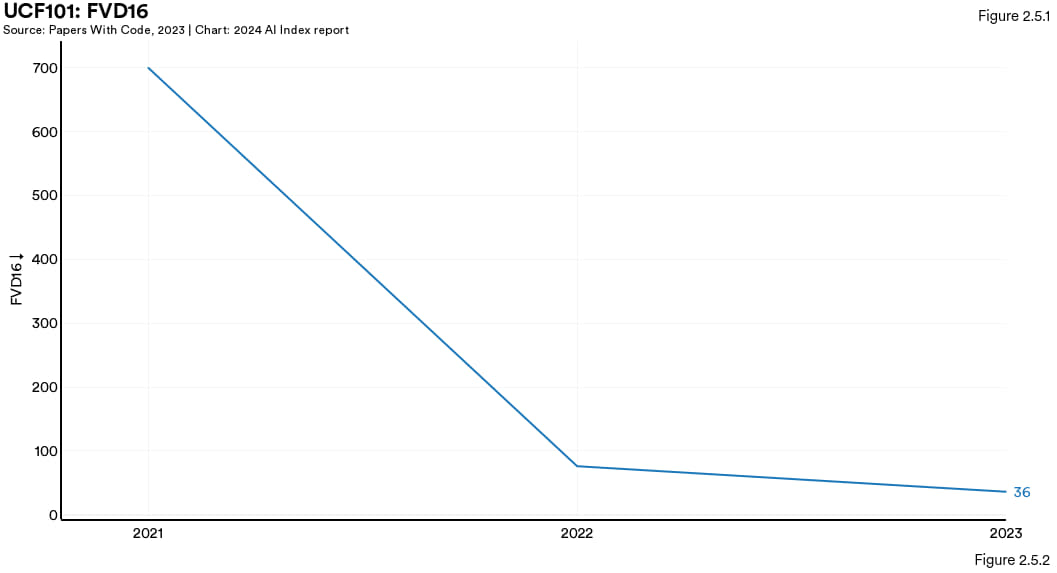
图2.5.2
2.6 推理
人工智能的推理是指人工智能系统从不同形式的信息当中得出逻辑合理结论的能力。例如,在一项通用推理挑战中,对人工智能系统推理的测试上下文有愈发多样化的趋势,包括视觉的(对图像的推理),道德的(理解道德困境),以及社会推理(驾驭社交场合)。
通用推理
通用推理指的是 AI 系统在多个广泛领域而非单一领域内的推理能力。例如,在一项通用推理挑战中,AI 可能需要处理多种主题的推理任务,而不仅仅是专注于例如棋类游戏等具体任务。
MMMU:用于专家级通用人工智能的大型多学科多模态理解与推理测试
近年来,人工智能系统的推理能力已有了大幅提升,原有的基准测试,如文本推理的 SQuAD 以及视觉推理的 VQA 的挑战性已不再足够,我们需要更复杂的推理测试。
为此,美国和加拿大的研究人员最近设计出了 MMMU(Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI),针对专家级通用人工智能的大型多学科多模态理解与推理测试。MMMU 涵括了六大学科约 11500 个大学级别的问题,涉及艺术与设计、商业、科学、健康与医学、人文与社会科学以及技术与工程 (图 2.6.1)。这些问题的形式多样,包括图表、地图、表格和化学结构等。MMMU 是迄今为止衡量人工智能感知能力、知识与推理能力最具挑战性的测试之一。截至 2024 年 1 月,得分最高的模型是 Gemini Ultra,其在所有类别中均处于领先位置,总分达到了 59.4% (图 2.6.2)。在大部分的单项任务中,顶尖模型的表现仍旧远低于人类专家的平均水平 (图 2.6.3),这个较低的分数足以证明 MMMU 在评估 人工智能推理能力方面的有效性。
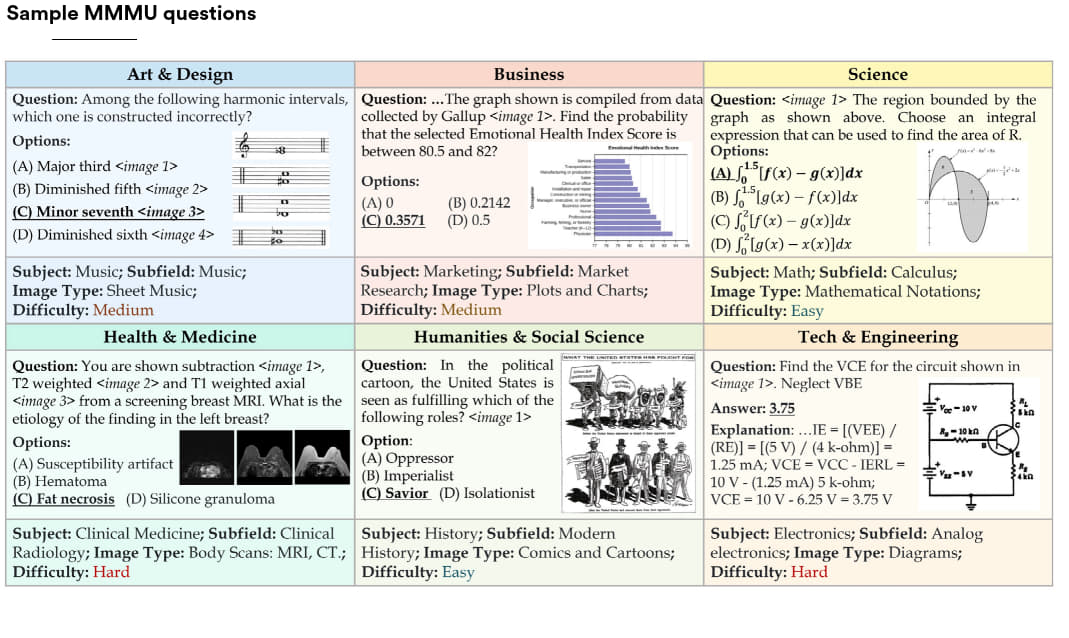
图2.6.1
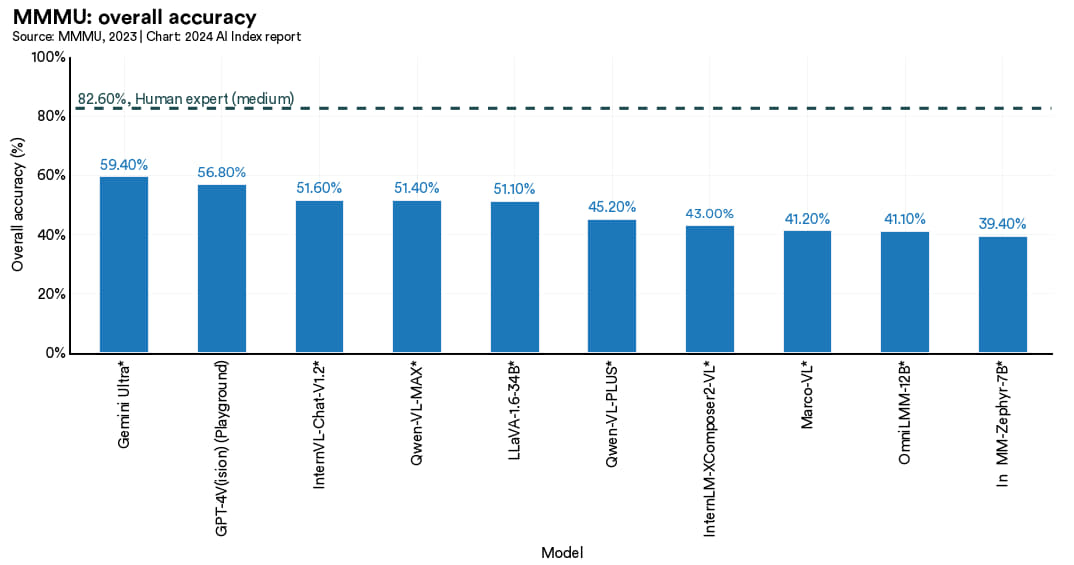
图2.6.2
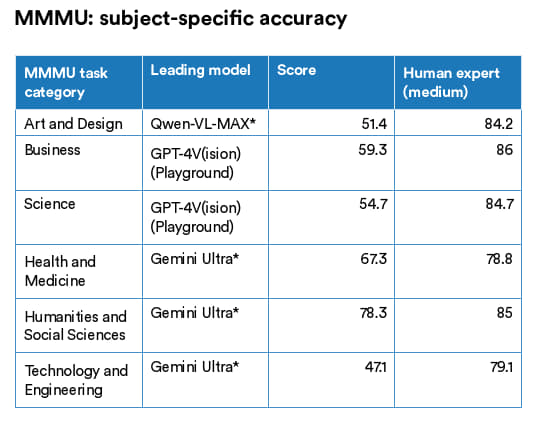
图2.6.3
数学推理
数学问题解决基准评估的是人工智能系统的数学推理能力。可以用范畴很广的一系列数学问题测试人工智能系统,低至小学水平,高到数学竞赛,不一而足。
GSM8K 是一个涵盖大约 8000 道小学数学文字题的数据集,目前在 GSM8K 上表现最出色的是某个版本的 GPT-4 版本(GPT-4 代码解释器),其准确率高达 97%,较去年最好成绩提高了 4.4%,跟 2022 年这个基准首次设立时相比则提高了 30.4%。
MATH 是一个由加州大学伯克利分校研究人员于 2021 年推出的竞赛级挑战性数学问题数据集。MATH 刚推出时,人工智能系统只能解决其中的 6.9%,但到了 2023 年,基于 GPT-4 的模型成功率已达 84.3%。
视觉推理
视觉推理测试的是人工智能系统在处理视觉和文字信息时的推理能力如何。
视觉常识推理 (VCR)
2019 年推出的视觉常识推理 (VCR) 挑战赛主要考察的是人工智能系统处理视觉信息的常识推理能力。参与挑战的人工智能不仅要根据图片回答问题,还需要对答案的合理性进行逻辑推理(图 2.6.13)。VCR 的表现用 Q->AR 得分来衡量,其检验的是人工智能选中正确答案(Q->A)及其理由(Q->R)的准确性。尽管人工智能表现尚未超越人类, 但从2022 到 2023 年,人工智能的表现已经提升了 7.93%(图 2.6.14)。

图 2.6.13
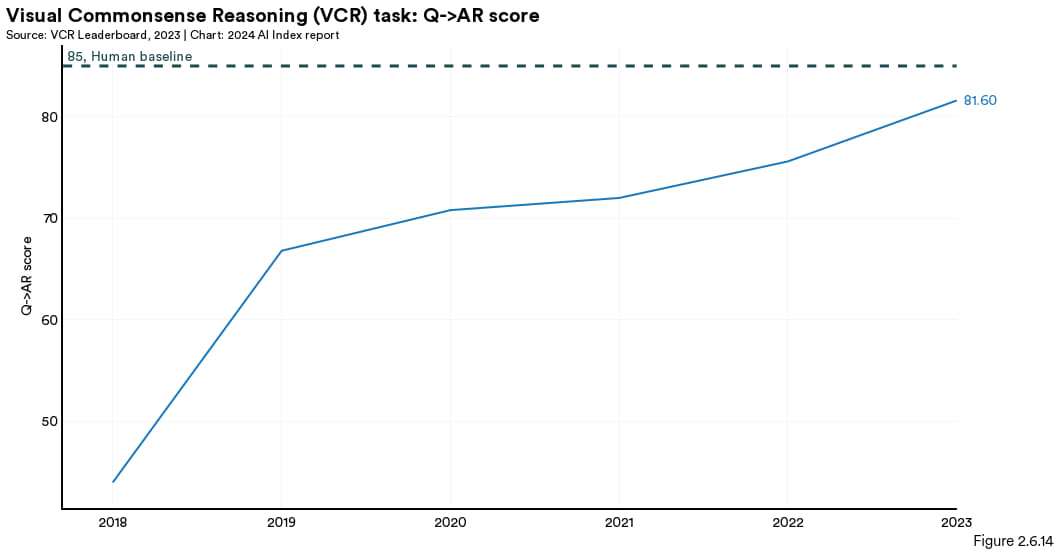
图 2.6.14
道德推理
人工智能将来将更广泛被用于需要严格道德判断的领域,如医疗和法律系统。因此,人工智能系统必须具备健壮的道德推理能力,这样才能在面临复杂的伦理和道德问题时做出恰当的判断与决策。
MoCa
人工智能模型在道德推理——尤其是能与人类道德判断相符的推理——方面的能力还未得到充分理解。为此,斯坦福大学的研究人员创建了一个包含道德元素的人类故事数据集(MoCa),然后向人工智能模型展示这些故事,并记录模型的反应,再用“离散一致性度量”来评估其与人类道德判断的吻合程度:得分越高,说明其判断越接近人类。研究发现,虽然没有任何一个模型能完全符合人类道德体系,但像 GPT-4 和 Claude 这样的新型大模型在道德一致性上表现更好,比起如 GPT-3 这样的小模型,显示出它们在扩展时能更好地适应人类的道德观(见图 2.6.16)。
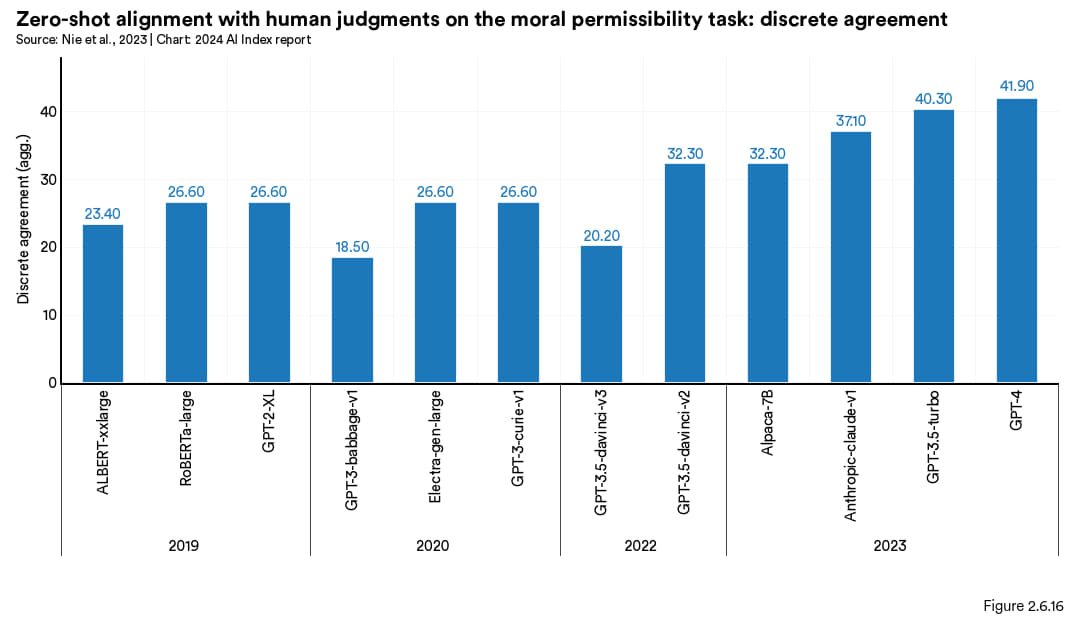
图 2.6.16
因果推理
因果推理评估的是人工智能系统理解因果关系的能力。随着人工智能系统日益成为我们生活的一部分,确保人工智能模型不仅可以解释自己的输出,还能在必要时更新其结论就变得格外重要,这是因果推理的核心之一。
评估大语言模型是否具备心智理论(theory-of-mind,ToM,如信念、意图及情感)的能力一直是人工智能研究的一大挑战。之前的方法在评估这种“心理理论”能力时既不充分也缺乏稳定性。为此,2023 年研究者们设计了一个新基准测试,BigToM,用来专门评价大语言模型在社交和因果推理方面的能力。BigToM 涵盖了 25 个受控测试和 5000 个模型生成的评估,效果被认为优于现有的同类测试。测试包括前向信念(forward belief,预测未来事件)、前向行动(forward action,基于预测的未来事件行动)及后向信念(backward belief,反向推断行动的原因)三个方面 。
在这个基准测试当中,GPT-4 的表现最佳,其理解他人心理状态的能力虽接近但未超过人类 (图 2.6.18, 图 2.6.19, 和 图 2.6.20)。具体来说,无论是前向信念还是后向信念,GPT-4 的表现与人类已经非常接近,而在前向行动的表现甚至略胜一筹。研究表明,LLM在ToM测试的表现趋势是向上的,如 GPT-4 的表现已超越前代 GPT-3.5。
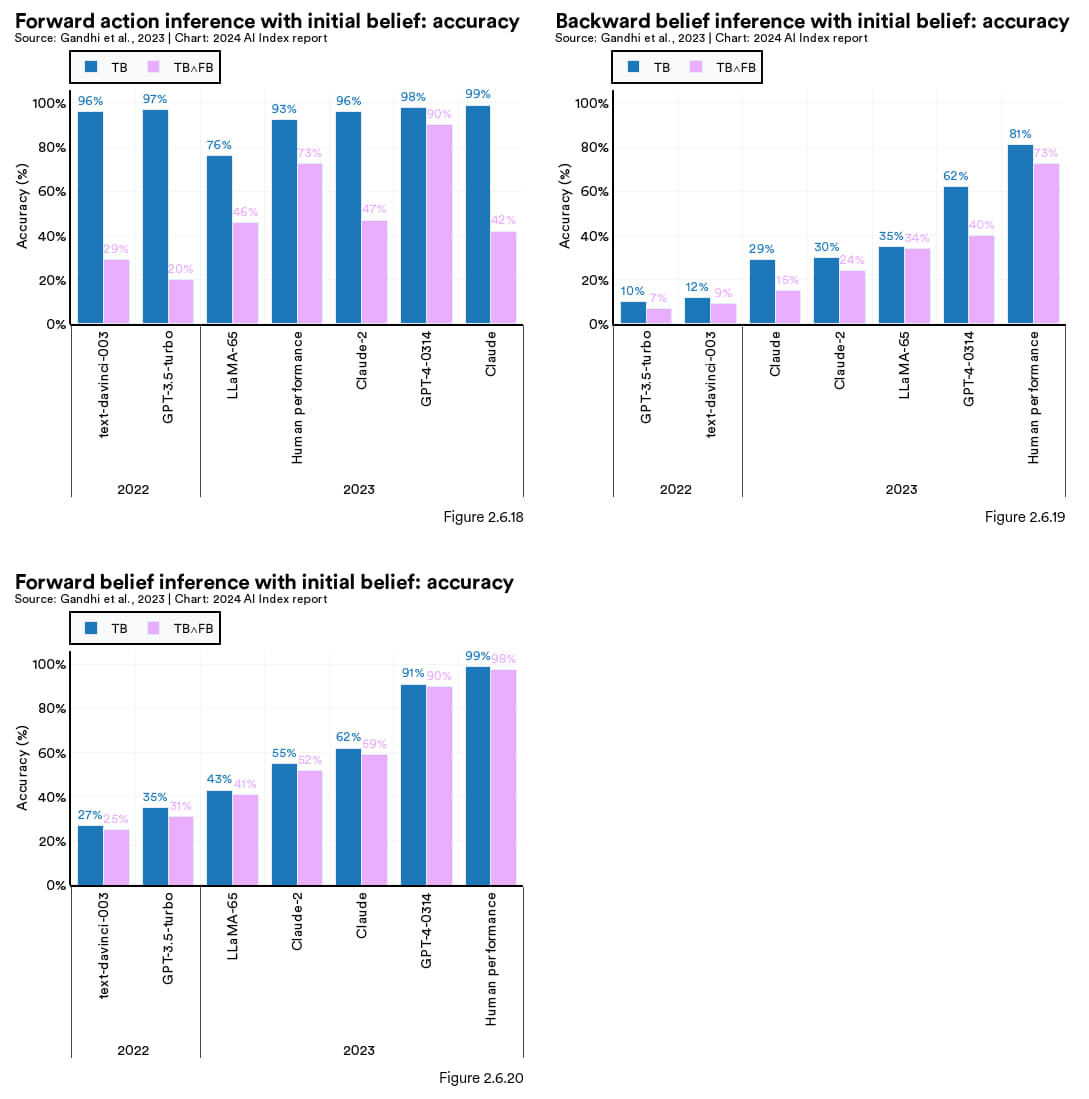
图 2.6.18、19、20
2.7 音频
人工智能系统擅长处理人类语言,其音频能力包括将口头表达转为文字并且识别讲话人。最近人工智能在生产合成音频内容上又取得进展了。
生成
2023 年是音频生成技术(能够制作从人声到音乐的各种合成音频)取得飞跃的标志性年份。这一年,几款突出的音频生成器的推出(如 UniAudio, MusicGen 和 MusicLM),更是让这一领域的发展受到广泛关注。
2.8 智能体
智能体(AI agents)是旨在特定环境下执行实现目标的自治或半自治系统,这是人工智能研究的一个令人兴奋的前沿。从学术研究和会议安排,到促进在线购物和假期预订,这些智能体有多种潜在应用。
通用智能体(AI agents)
这一部分主要介绍了那些能够在各种通用任务环境中灵活工作的智能体的基准测试和研究。
新的基准测试AgentBench是专门用来评估基于大语言模型 (LLM) 的智能体的。该基准测试涵盖了八种不同的互动场景,如网页浏览、在线购物、家庭管理、解谜以及数字卡牌游戏等 。研究涉及了包括 OpenAI 的 GPT-4、Anthropic 的 Claude 2 和 Meta 的 Llama 2 在内的超过 25 种智能体。其中GPT-4 的表现最佳,总得分达 4.01 分,明显超过了 Claude 2 的 2.49 分 (图 2.8.2)。此外,研究显示,2023 年推出的大语言模型在智能体方面表现均优于以往的版本。AgentBench 团队还指出,智能体在某些测试环节仍表现不佳,主要是因为其在长期推理、决策和遵循指令方面的能力有限。
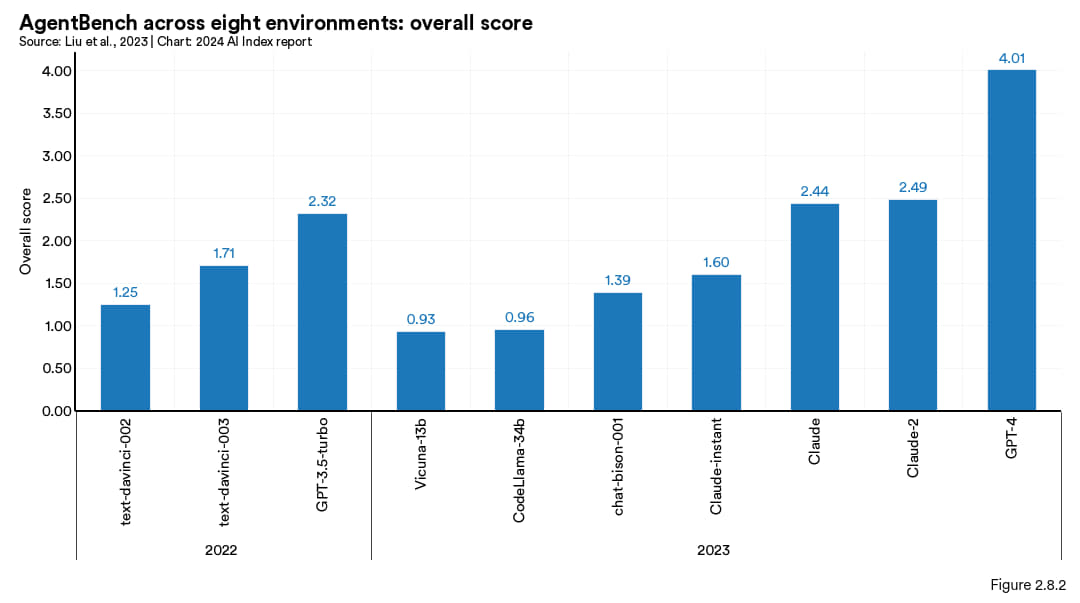
图 2.8.2
针对特定任务的智能体
本节介绍一些专门为解决特定类型任务——比如解数学题或进行学术研究——而设计的智能体,及其性能的研究成果。
MLAgentBench
MLAgentBench 是一个新的基准测试平台,主要用于评估智能体在科学研究的表现。具体而言,该基准测试的是人工智能系统是否能成为合格的计算机科学研究助理,基准设计了 15 种不同的研究任务来考察它们的能力。这些任务包括在 CIFAR-10 图像数据集上优化基线模型和在 BabyLM 上训练一个涵盖超过 1000 万词汇的语言模型。参与测试的有多种基于 LLM 的智能体,如 GPT-4, Claude-1, AutoGPT 以及 LangChain。测试结果表明,虽然智能体展现出了研究的潜力,但其在不同任务上的表现差异较大。比方说,部分智能体在执行像 ogbnarxiv 这样的任务上成功率超过 80%,而在执行 BabyLM 的语言模型训练任务则全数失败(图 2.8.5)。在这些测试当中,GPT-4 的表现均是最优秀的。
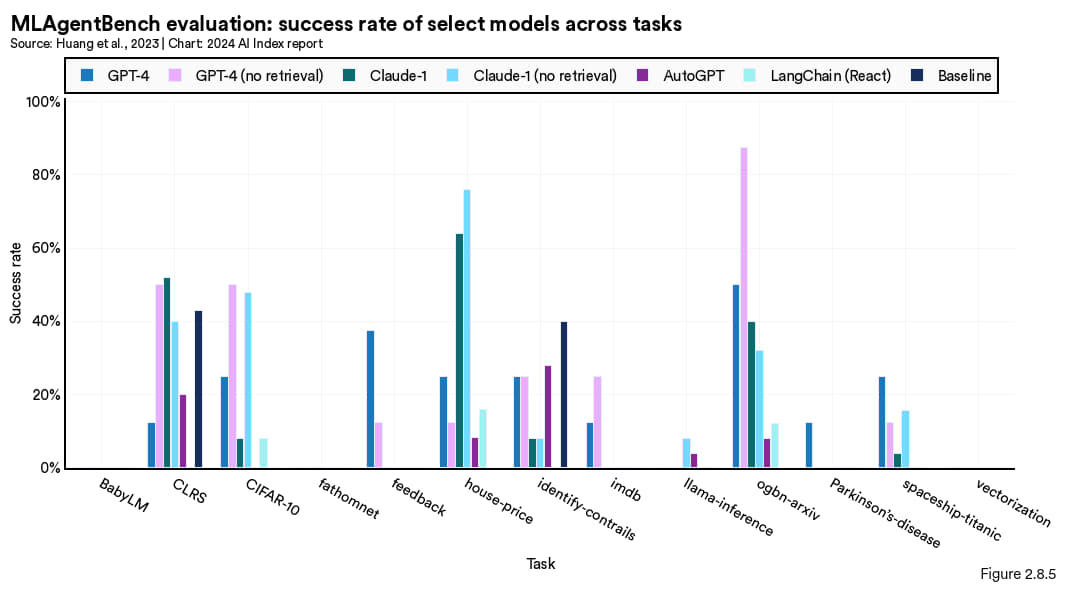
图 2.8.5
2.9 机器人
人工智能已逐渐集成到机器人之中,强化了机器人执行复杂任务的能力。尤其是随着基础模型的兴起,这种集成使得机器人可以迭代地从周围环境学习,灵活地适应新环境,并自主作出决策。
焦点研究:PaLM-E
PaLM-E 是谷歌的一款新的人工智能模型,模型结合了机器人与语言建模技术,用来处理诸如机器人操控以及知识任务(如问答和图像描述)等现实世界的任务。该模型在多项机器人基准测试中均展现出优异性能。在让机器人操控物体的任务与动作规划(TAMP)领域,PaLM-E 在具身视觉问题回答与规划方面均超过了之前的SayCan 与 PaLI 等最佳方法(图 2.9.2)。在机器人操控任务中,PaLM-E 检测失败(机器人执行闭环规划的关键步骤)的能力超过了竞争模型(PaLI 和 CLIP-FT,图 2.9.3)。
PaLM-E 的重要性在于,它证明了语言建模技术以及文本数据可以提升人工智能系统在非语言领域(如机器人技术)的性能。PaLM-E 还突出表明,目前已经有能够进行实际交互和高级推理的语言熟练机器人。
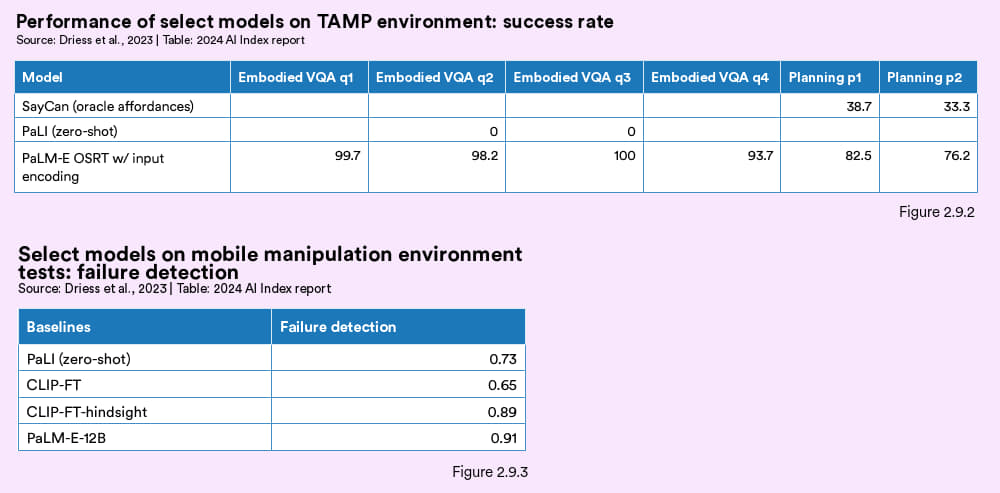
上图: 图 2.9.2 下图:图 2.9.3
2.10 强化学习
强化学习是通过与之前动作互动来训练人工智能在特定任务上取得最佳表现。如果系统实现想要的目标,则会获得奖励,如果失败,则会受到惩罚。
基于人类反馈的强化学习(RLHF)
在增强了GPT-4与Llama 2等最先进语言模型后,强化学习开始流行起来。 2017 年引入的强化学习将人类反馈纳入到奖励函数内,令模型可以训练成具备如帮助性与无害性等特点。
如图 2.10.1 所示,报告用了 RLHF 的基础模型的数量在逐年增加:2021 年还没有模型采用 RLHF,2022 年增至7个,而 2023 年则达到了16个。RLHF 的增长趋势也得到了众多领先的大语言模型的实际使用情况的支持,这些模型均通过 RLHF 显著优化了自身性能(见图 2.10.2)。
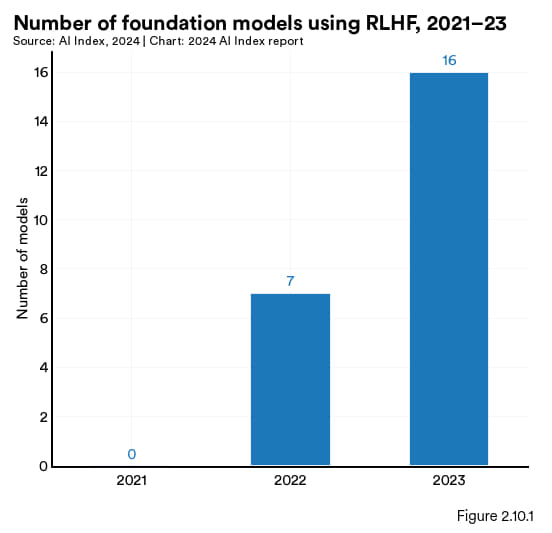
图 2.10.1

图 2.10.2
2.11 大语言模型的特性
焦点研究:挑战涌现行为的看法
许多论文声称大语言模型(LLM)展现出了“涌现能力”,也就是在规模变得更大时会突然冒出新的能力。这种现象让人担忧,更大的模型可能带来不可预测甚至难以控制的新功能。
不过i,斯坦福大学的最新研究却挑战了这一看法,该研究认为,被认为的“新能力涌现”往往是用来评估的基准的折射,而不是模型本身的特性。研究表明,当评价模型的标准采用非线性或不连续的指标(如多选题评分)来评估模型时涌现能力似乎会更明显。相反,如果用连续性或线性的评估指标时,这些能力基本上就消失不见了。通过对 BIGbench 基准测试进行深入分析,该研究发现,在 39 项测试中仅有 5 项有涌现能力(图 2.11.1)。这一发现为人工智能安全与对齐研究提供了新的视角,挑战了人工智能模型必然会随着规模增加而学到新的,不可预测行为的普遍看法。
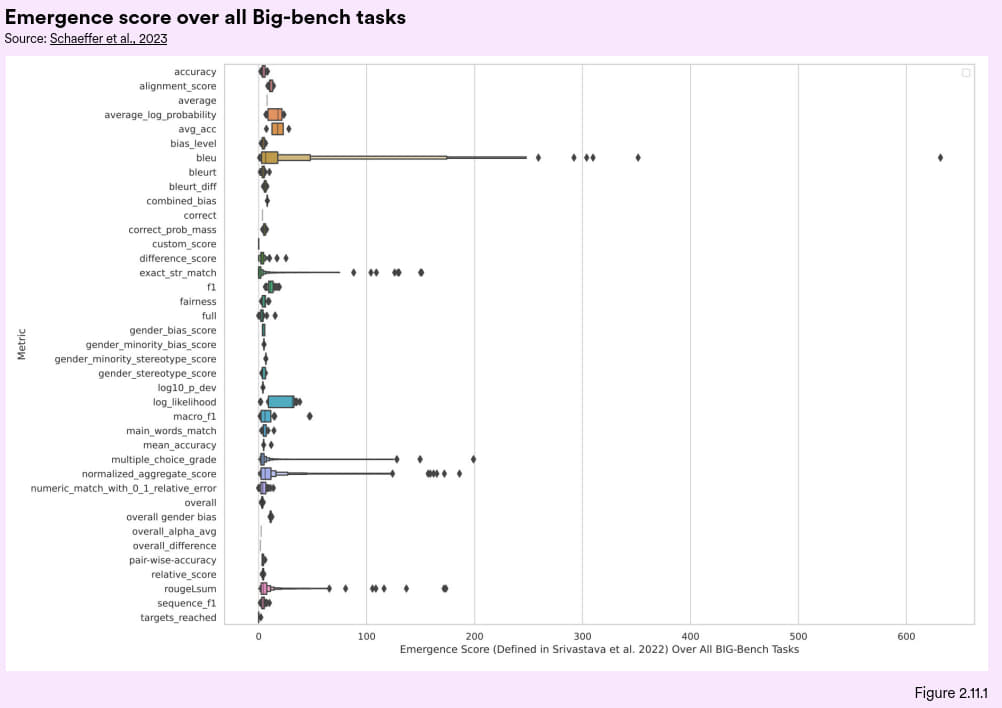
图 2.11.1
焦点研究:大语言模型的性能变化情况
像 GPT-4, Claude 2 与 Gemini 这样的公开可用的闭源大语言模型,其开发者经常会基于新的数据与用户反馈进行更新。但对于这些更新后的模型在性能上的变化,目前研究并不多。
斯坦福与伯克利的研究团队对公开可用的大语言模型性能随时间的变化进行了探究,发现其性能实际上波动很大。研究比较了 2023 年 3 月的 GPT-3.5 与 6 月的GPT-4 ,结果显示后者在多项任务上性能均有所下降。比方说,6 月版的 GPT-4 在编写代码方面比 3 月版下降了 42 个百分点,在回答敏感问题方面下降了 16 个百分点,在部分数学任务上则下降了 33 个百分点 (见图 2.11.2)。研究还指出,GPT-4 遵循指令的能力会随时间推进而逐渐减弱,这可能是性能整体下降的一个原因。此项研究突出表明大语言模型的性能是会随时间变化的,建议用户应对此保持关注。
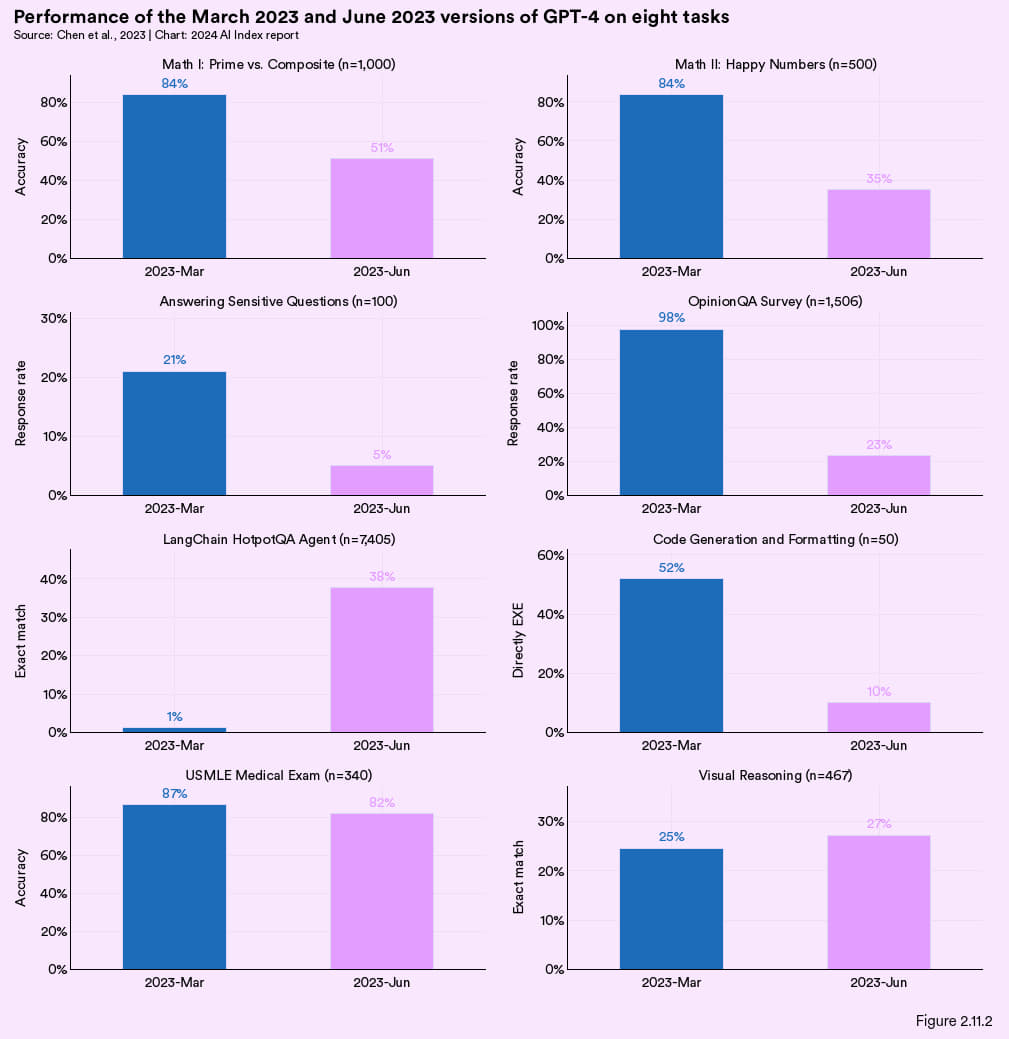
图 2.11.2
焦点研究:大语言模型不擅长自我校正
大语言模型的推理能力有限,有时候还会产生幻觉。提议的解决方案之一是让模型自我修正,也就是让模型识别和修正自己的推理缺陷。但目前我们对大语言模型能否做到这一点仍知之甚少。
为此,来自 DeepMind 与伊利诺伊大学厄巴纳 - 香槟分校的研究人员对 GPT-4 进行了三项推理测试:GSM8K (小学级数学), CommonSenseQA (常识推理)以及 HotpotQA (跨文档推理)。研究发现,在没有指导让模型自己对自我修正做出决策的测试里,GPT-4 在所有指标上的表现军出现下降(编者注:也就是说,越改越错 ,参见图 2.11.3)。
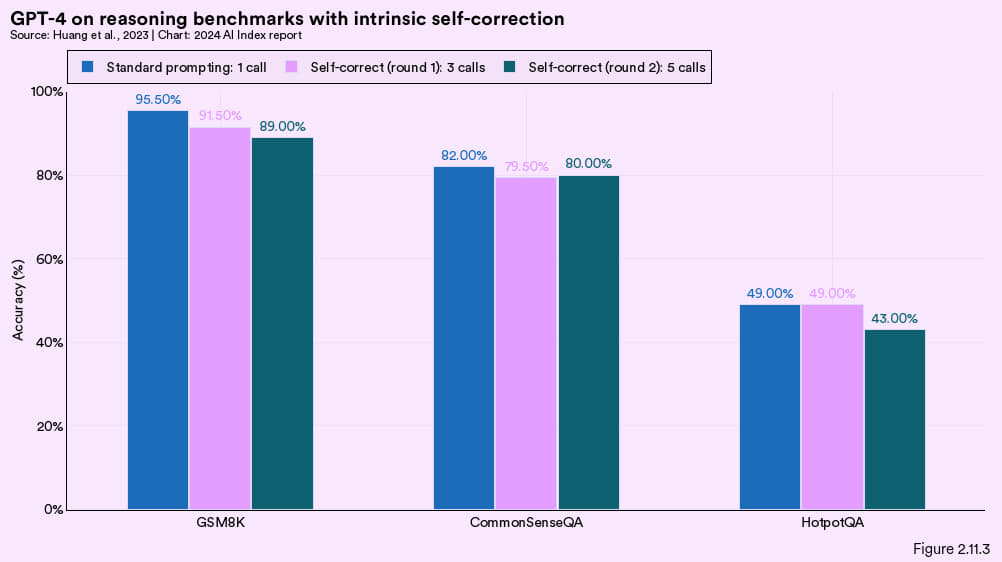
图 2.11.3
闭源模型与开源模型的性能对比
随着大语言模型的日益普及,对其不同程度的可达性之争也愈发激烈。部分模型依旧封闭,只有其开发者方可使用(如谷歌的 Gemini)。而类似 OpenAI 的 GPT-4 与 Anthropic 的 Claude 2 这样的模型则提供了有限的访问权限,可以通过 API 公开访问。不过,这些模型的权重并未完全公开,这意味着公众不能自行修改模型或进行更深入的详细检查。不过Meta 的 Llama 2 以及 Stability AI 的 Stable Diffusion 则采取了开放的方式,完全公开了他们的模型权重。开源模型则是任何人都可以修改,也可以自由使用。
大家对开源闭源的优缺点看法不一。部分人对开源比较认同,认为开源可以对抗市场垄断、培育创新,增强人工智能生态体系内的透明度。有人则认为开源模型会带来可观的安全风险,如会帮助制造虚假信息或生物武器,因此应该谨慎对待。
在开闭之争的背景下,认识到一点很重要,那就是当前的证据显示,开源模型与封闭模型之间存在着明显的性能差异。 图 2.11.4 和图 2.11.5 对比了顶级的闭源与开源模型在一系列基准测试上的表现。闭源模型在所有选定的基准测试上的表现军优于开源模型。具体而言,在 10 个选定的基准测试中,闭源模型的相对性能优势中位数为 24.2%,小至数学任务(如 GSM8K )的 4.0% ,大至智能体任务(如 AgentBench) 的 317.7%。
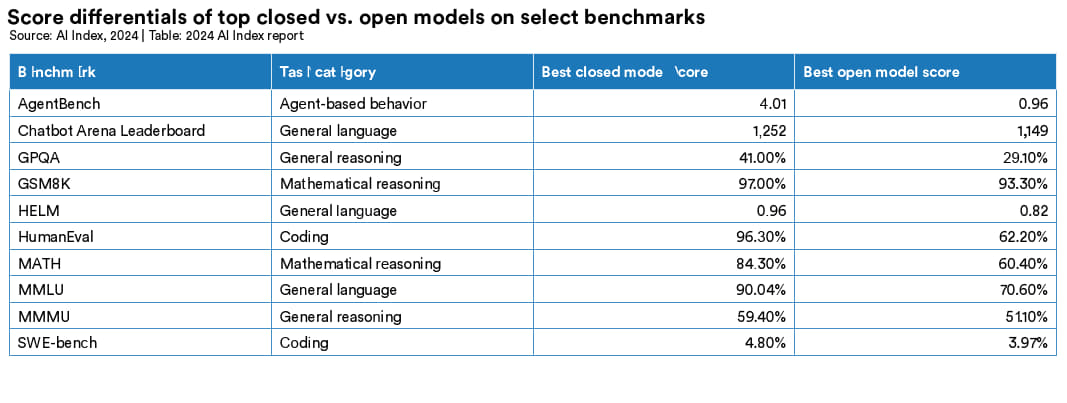
图 2.11.4
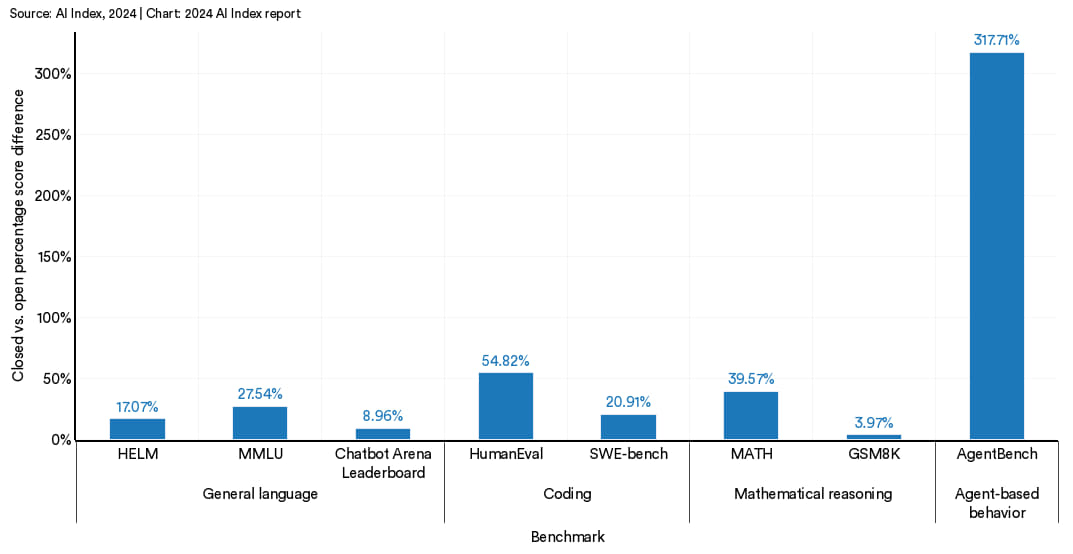
图 2.11.5
2.12 大语言模型改进技巧
提示
提示是人工智能流水线的关键部分,就是用自然语言给模型发指令,描述模型应该执行的任务。掌握写出有效提示的技巧,可以在不需要对模型本身做出改变的情况下,大幅提升大语言模型的表现。
焦点研究:思维图(Graph of Thoughts,GoT)
思维链(Chain of Thoughts,CoT)和思维树(Tree of Thoughts,ToT)这些提示方法已知可提升大语言模型在推理任务上的表现。2023 年,欧洲的研究者又提出了一种新的提示方法——思维图。思维图就是让模型用图谱结构来组织思路,这种方法更灵活,跟人类推理方式类似,被证明很有潜力(图 2.12.1)。此外,研究者还设计了一种模型架构来实现 GoT,结果表明, 在某项排序任务上,GoT的输出质量比 ToT 提高了 62%,成本同时降低了约 31%(图 2.12.2)。
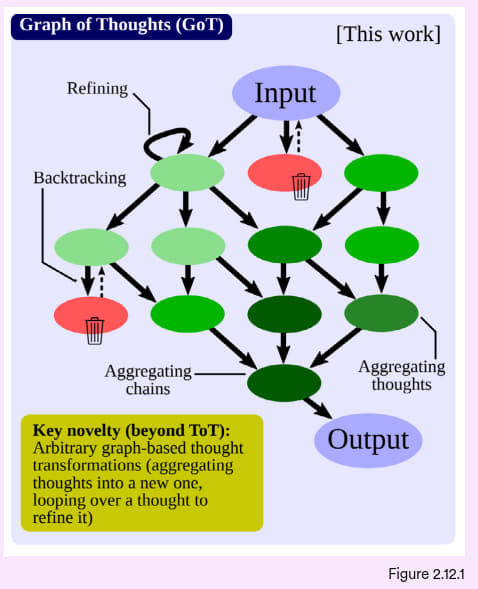
图 2.12.1
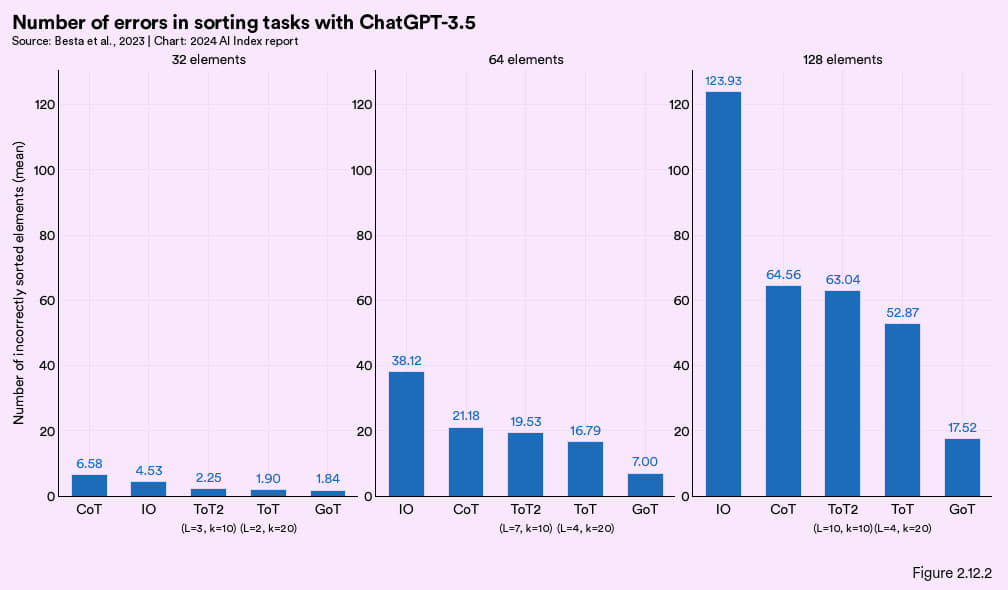
图 2.12.2
焦点研究:用提示优化提示(Optimization by PROmpting ,OPRO)
DeepMind 最近介绍了一种新的提示技术,Optimization by PROmpting,也就是用提示来优化提示。这种方法让大语言模型迭代生成提示来提升算法性能。OPRO 会用自然语言引导大语言模型根据问题的描述及之前的解决方案来生成新的提示 (图 2.12.3)。新生成的提示旨在增强人工智能系统在特定评测标准上的性能。与“让我们一步步思考”等其它提示方法相比, 在所有 23 个 BIG-bench Hard 任务中OPRO几乎都能显著提高准确度 (图 2.12.4)。

图 2.12.3
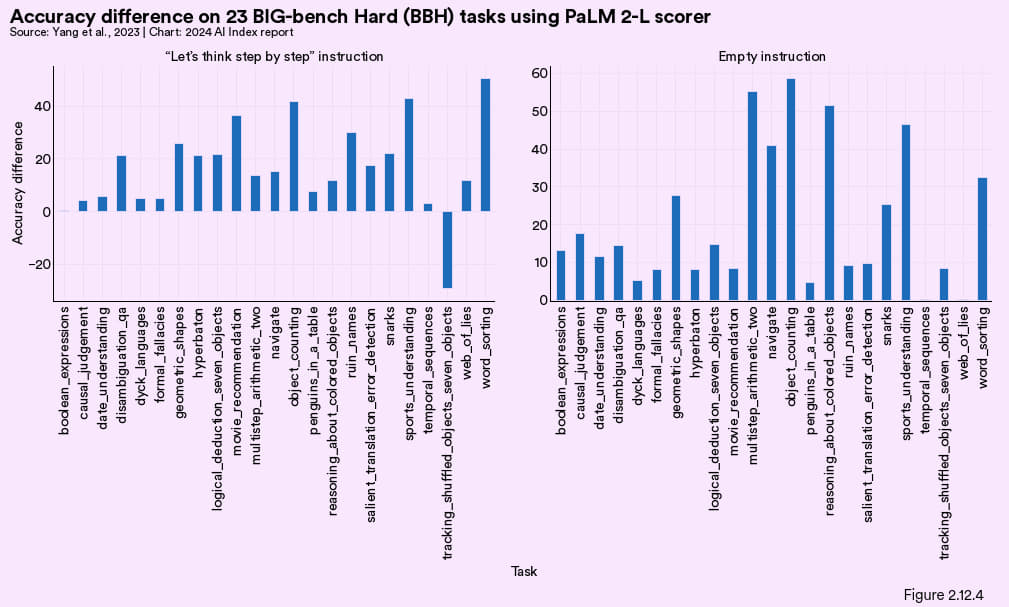
图 2.12.4
微调
作为一种提升大语言模型性能的方法,微调已经逐渐流行起来。它包括在规模更小的数据集上对模型进行额外的训练或调整。通过微调,不仅可以提升模型的整体表现,还可以增强其在特定任务上的性能,并能让我们更精确地控制模型的行为。
焦点研究:QLoRA
2023 年华盛顿大学的研究人员开发出了一种名为 QLoRA 的模型微调新技术,该技术可显著降低对内存的需求,使得在仅有的 48 GB GPU 上就能完成对 650 亿参数规模模型的微调,且还能维持完整 16-bit 微调的性能。通常对一个有 650 亿参数的 Llama 大语言模型进行微调需要约 780 GB 的内存,相比之下,QLoRA 的效率提高了近 16 倍。通过引入如 4-bit NormalFloat (NF4)、双重量化及页面等优化技术,QLoRA 极大提升了性能。使用 QLoRA 训练的 Guanaco 模型在 Vicuna 比较测试中展示了出色性能,表现甚至超过了 ChatGPT 等模型(图 2.12.5)。值得关注的是,这些 Guanaco 模型只需用一个 GPU 微调 24 小时即可完成,说明模型优化技术已经取得进步,这意味着将来创建更高效模型消耗的资源会更少。
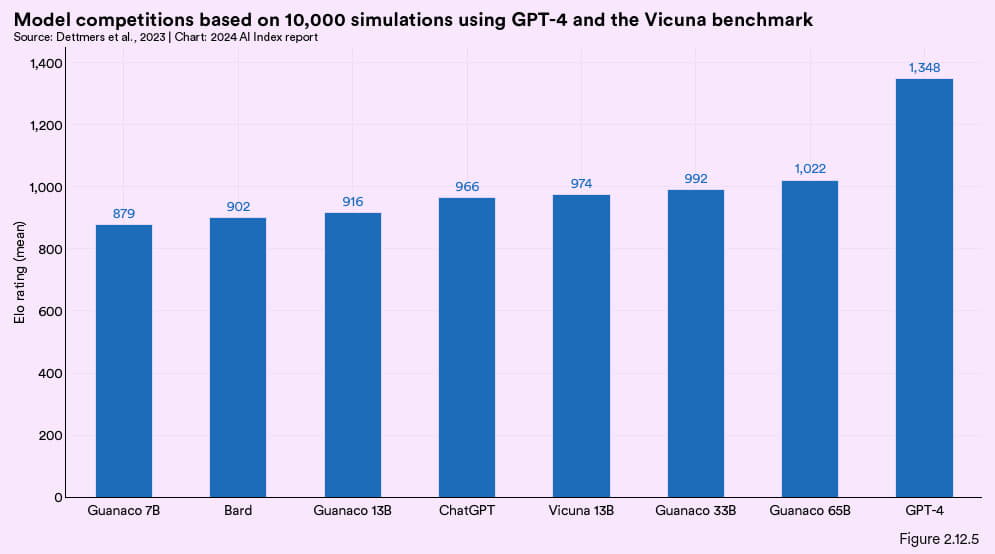
图 2.12.5
2.13 人工智能系统的环境影响
本节分析了人工智能系统的环境影响趋势,特别强调了在透明度和环境意识方面的进步。
训练
图 2.13.1 展示的是选定的大语言模型在训练过程中的碳排放量 (以吨为单位) 与人类参考数据的比较。不同模型的数据差异很大。比方说,Meta 的 Llama 2 70B 模型碳排放量大约是 291.2 吨,大约相当于美国普通人一年排放总量的 16 倍。不过,Llama 2 的排放量仍然少于训练GPT-3的碳排放量,据报道约为 502 吨。
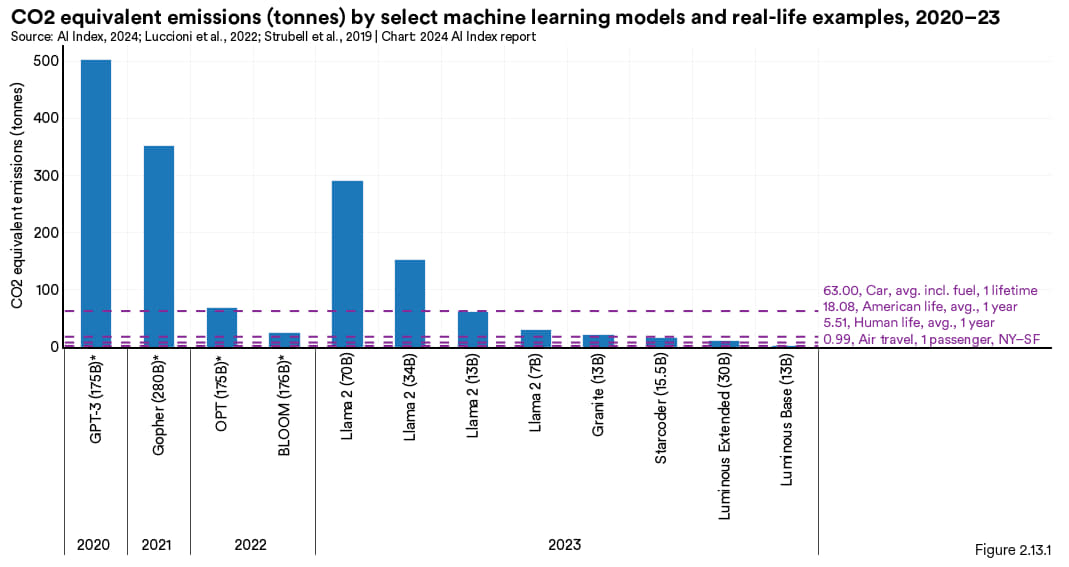
图 2.13.1
排放估算的差异是由于模型大小、数据中心的能效以及电网碳强度等因素所致。图 2.13.2 展示的是选定模型碳排放相对模型大小的关系。一般来说,模型规模较大碳排放量也越大,这个趋势在 Llama 2 模型系列表现得很明显,因为都是用同一台超级计算机训练的 (Meta 的Research Super Cluster)。不过,如果用能效较低的电网来训练的话,模型规模小碳排放仍可能会很高。部分估算表明,模型的碳排放量随着时间的推移已有所下降,这可能与训练机制日益高效有关。图 2.13.3 展示的是选定模型碳排放量与功耗的情况。
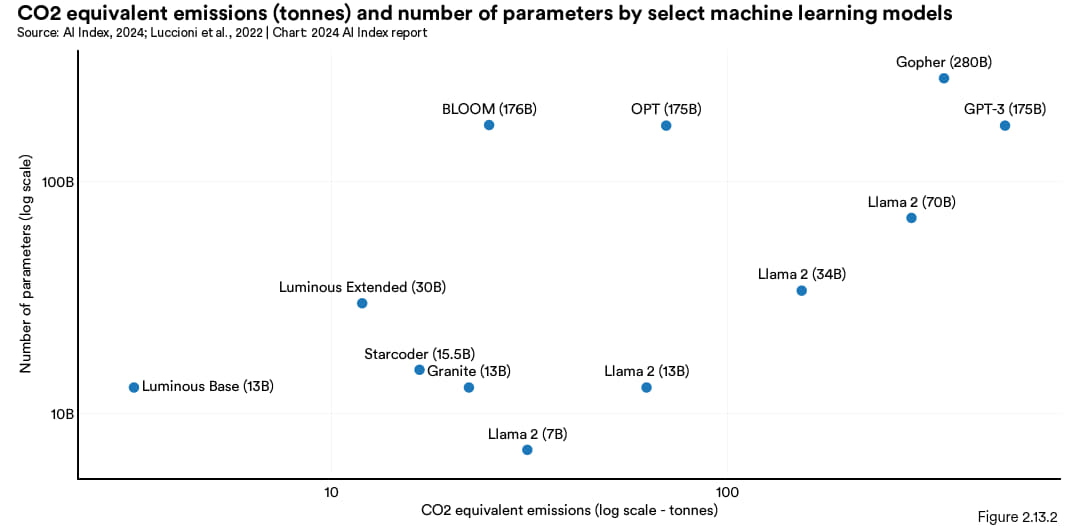
图 2.13.2
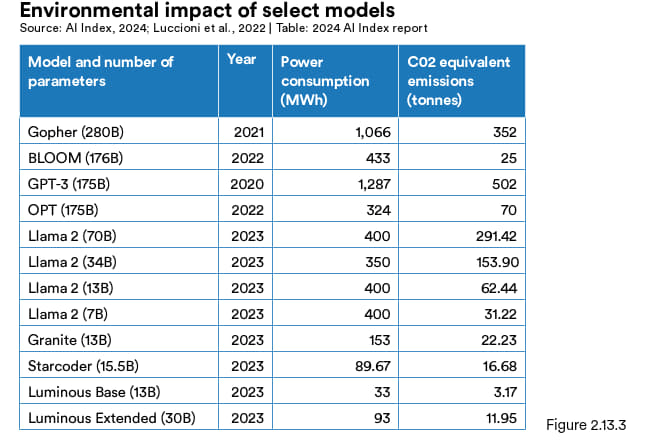
图 2.13.3
延伸阅读:
2024人工智能指数报告(一):研发